from sklearn import tree
import numpy as np
import matplotlib.pyplot as plt
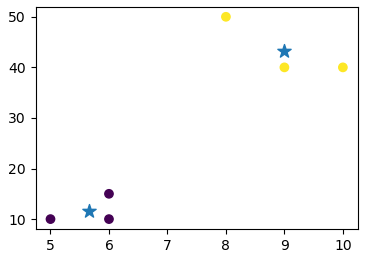
x = np.array([[5,10],[8,50],[6,10],[10,40],[6,15],[9,40]]) # 対象データ
model = KMeans(n_clusters=2, random_state=100).fit(x) # k-means実施
plt.scatter(x[:,0], x[:,1], c=model.labels_) # 散布図描画
plt.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1],s=100, marker='*')
plt.show()