import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize
x = np.array([-1, -0.8, -0.6, -0.4, -0.2, 0, 0.2, 0.4, 0.6, 0.8, 1])
y = np.array([ 2, 1.8, 1.7, 1.6, 1.8, 2, 2.2, 2.1, 2.0, 2.3, 2.4])
def least_square(w, x, y, d, lamda=0):
y_ = np.poly1d(w)(x)
error = np.sum((y - y_) ** 2) / len(y_) # 最小二乗法
return error
d = 1 # 次数
w_init = np.ones(d+1)
result = minimize(least_square, w_init, args=(x, y, d)) # 関数の値を最小化する
w = result.x #多項式の係数
print(w) # 係数を出力
plt.scatter(x, y)
plot_x = np.arange(-1,1.1,0.05)
plt.plot(plot_x, np.poly1d(w)(plot_x)) # グラフを描画
plt.show()
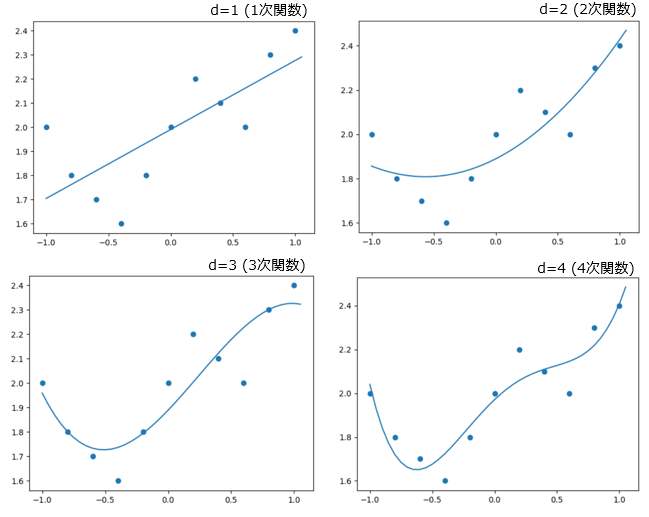
上記を見ると、多項式の次数が大きくなるに従い、与えられた関数に無理やりフィッティングさせた感が出ております。
これを過学習といって、定めた区間では誤差は小さくなりますが、定めた区間以外では全く合わないので好ましくありません。
これを解消する手法の一つにラッソ回帰、リッジ回帰などがあります。