
|
前提知識
・python
・sklearn-KMeans
・重心
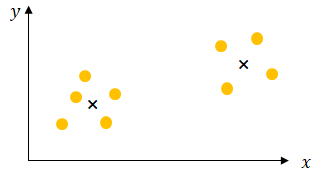
k-meansとはクラスタリングの手法の一つで、以下の様にもともと属性が定義されていないデータを分割します。
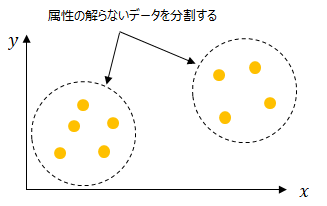
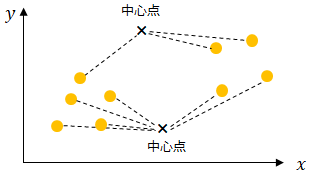
k-meansの手法は以下のとおりです。最初にランダムに分割したいクラスターの数だけ中心点を置き(この場合は二つ)、
各データの近くにある方の中心点と繋げます。
次に繋がっているデータの重心を求め、その重心に中心点を移動させます。
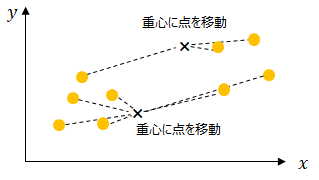
移動させた中心点から近いデータを再度繋げます。
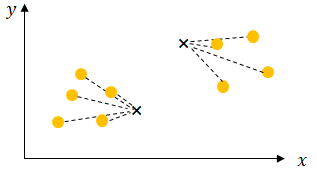
そして再び重心を求めるというステップを繰り返せば、最終的に中心点が移動しなくなります。これでクラスタリングが完了しました。
■pythonによるシミュレーション
scikit-learnというデータ分析に特化したライブラリの中のkmeansを使います。
・pythonバージョン:Ver3.8で確認
・必要ライブラリ:numpy,matplotlib,scikit-learn (インストール方法はこちら)
・必要ファイル:kmeans.zip(プログラムファイル, 訓練データ)
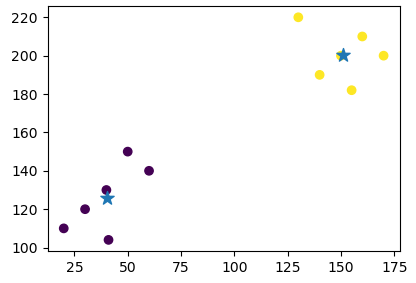
結果は以下のとおり、うまくクラスタリングする事ができました。
サブチャンネルあります。⇒ 何かのお役に立てればと
|
|