
|
前提知識
・確率過程
・強化学習
マルコフ決定過程(Markov Decision Process,MDP)とは確率過程の一種で、現在の状態とその時の行動結果から確率論的に将来の状態を決定し、
かつ行動結果に対して報酬を紐づける状態遷移モデルで、以下式で表します。これは主に強化学習の分野で使用されます。MDPとマルコフ過程の違いは、MDPはマルコフ過程に対して行動と報酬の概念が加わっている所です。

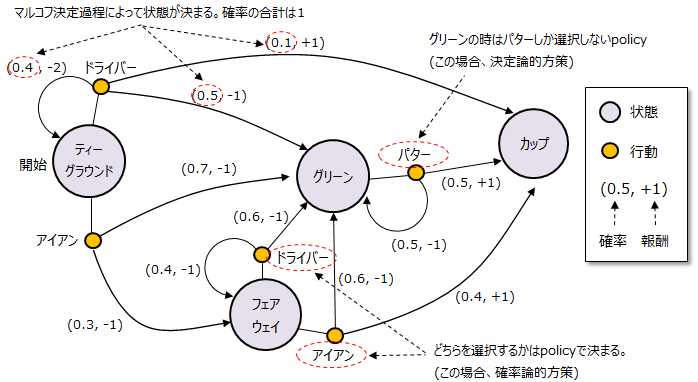
ゴルフを具体例に説明します。以下がMDPの状態遷移図になります。ゴルフボールのある位置を「状態」、打つクラブの種類を「行動」とします。ティーグラウンドから開始し、ドライバかアイアンを選択して打ちます。
どちらを選択するかを決める考え方の事を方策(Policy)といい、以下で表します。

上記において、状態が決まったらアクションが一意に決まることを決定論的方策(Deterministic Policy)といい、確率的にアクションが変わることを確率論的方策(Stochastic Policy)といいます。
さてここでドライバーが選択された場合、ボールの行き先がグリーン、ティーグラウンド(OB)、カップ、いずれになるかマルコフ決定過程によって決定されます。この時、各状態に対する確率値の合計は1となります。
カップに入った場合は報酬が+1、できるだけ少ない打数でカップに入った方が良いので、カップに入る以外はペナルティとして報酬はマイナスとなります。
例えば、今の状態がティーグラウンドでドライバーを打つ確率は(2)式より以下で表します。
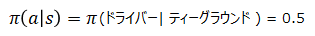
ドライバーを打つと決まり、その時カップの状態になる確率は(1)式より以下で表します。
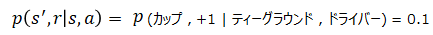
サブチャンネルあります。⇒ 何かのお役に立てればと
|
|