
|
前提知識
・強化学習とは
・pythonとは
・Blackjack
こちらで強化学習について説明しましたが、ここではモンテカルロ法を使った強化学習の実装例を説明します。
題材はOpenAI gymというpythonライブラリに実装されているBlackjack(ブラックジャック)を用い、勝率を上げる様に学習させます。
■モンテカルロ法(MC法)とは
エピソードが終わる前にQ値を遂次更新する手法はTD学習といいますが、対して、MC法はエピソードが終わった時点でQ値を更新し、以下式で表します。
MC法はエピソードが終わった結果でQ値を更新するのでQ値の精度が高いというメリットがありますが、更新が遅くなるのでオンライン学習が難しいというデメリットがあります。
※ なおMC法といえば、こちらで説明しているランダムサンプリングによって数値計算を近似的に算出する方法をイメージする人もいるかと思います。
ここで説明しているMC法も、報酬を得るまではランダムサンプリングなのでMC法と言っているのではないかと個人的に推測してます。
<実例でモンテカルロ法を理解>
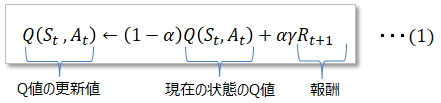
ブラックジャックを例にモンテカルロ法を説明します。ブラックジャックは先ず自分と相手(ディーラー)に2枚ずつカードを配ります。相手のカードの1枚は伏せられて解らない状態で自分がカードを引いていき、
これで良いと思ったら、今度は相手が18以上になるまでカードを引きます。下の例(1エピソード目)では自分が勝つことは出来ました。
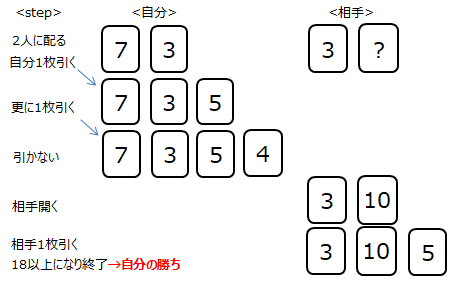
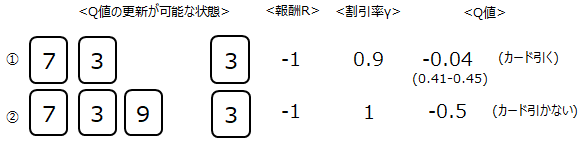
この時報酬を受け取りQ値の更新が可能なのは、以下3つの状態(State)です。相手のカード情報が影響するのは最初に見えているカードのみです。
なぜなら他のカードは自分が行動をとる時点は未知の情報なので、自分の行動を決める材料にならないからです。
報酬はそれぞれの状態に対して1の報酬が与えられますが、報酬に対して割引率γを考慮します。割引率とは、報酬を貰う決め手になったのは下記③なのに対して、
①②は報酬を貰う直接の状態から離れた状態のため、報酬を割り引くというものです。
(1)式よりQ値を求めます。Q値の初期値は0、αは0.5の前提で計算した結果となります。
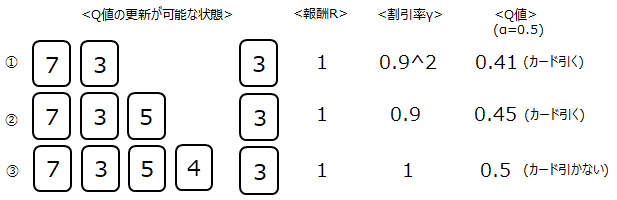
次に2エピソード目を行います。結果は以下となりました。最初に配ったカードが全く同じでしたので、その状態のQ値は1エピソード目のQ値を使って新たなQ値を求めます。
(その後の引いたカードは異なるので、初期値0としてQ値を求めます)
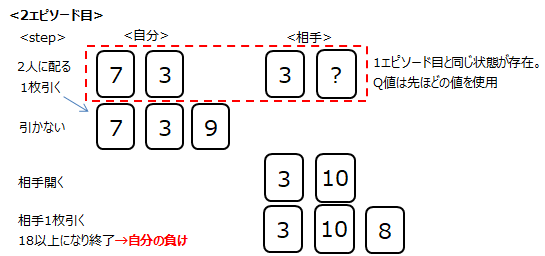
Q値の計算結果は以下。この様に何万エピソードを繰り返し、全ての状態のQ値の最適値を求めていきます。
■Pythonによるシミュレーション
上記ブラックジャックの例で、勝負に勝つようにQ値を学習していきます。
・pythonバージョン:Ver3.8で確認
・必要ライブラリ:numpy , OpenAI gym(インストール方法はこちら)
・プログラムファイル:RL_bj.zip
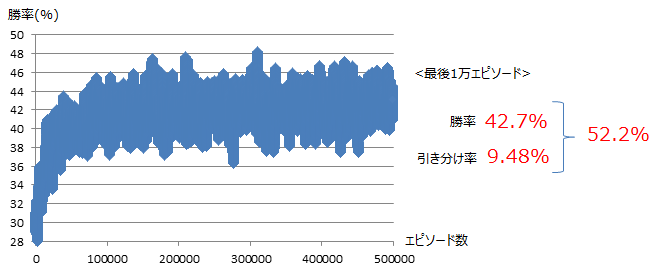
結果は以下のとおり。1000エピソード移動毎の勝率を示しております。学習する事で勝率を上げる事ができ、最終的に42.7%まで勝率を上げる事ができました。(引き分けを考慮すると52.2%に到達)
<単純アルゴリズムとの比較>
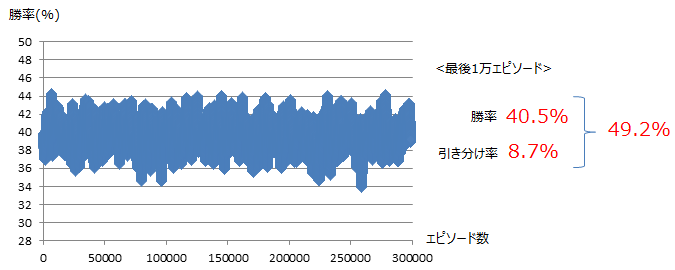
上記が果たして本当に優れた結果なのかを、他のアルゴリズムでの結果と比較します。アルゴリズムとしては、自分のカードの合計が18以上になるまでカードを引き続け、
18以上になったらカードを引くのを止めるというものです。結果は以下のとおり。強化学習の方が高い勝率を得ていることが解りました。
・プログラムファイル:RL_bj_vs.zip
サブチャンネルあります。⇒ 何かのお役に立てればと
|
|