
|
前提知識
・pythonとは
・強化学習とは
・Cartpole
強化学習の具体例としてOpenAI gymのCartPoleを行います。この問題はブラックジャックの例とは異なり、
状態(カートの位置/速度、ポールの角度/角速度)が連続系です。この場合、状態量を離散化する必要があります。
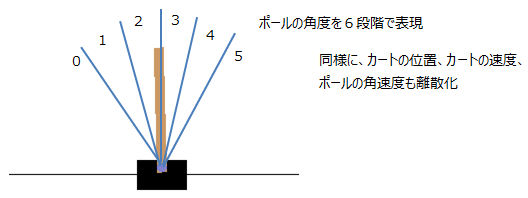
■Q値の設定
離散化後、状態量(カートの位置/速度、ポールの角度/角速度)の全てのパターンに対してQ値(左へカートを動かすか、右へ動かすか)を学習していきます。
今回の場合、状態量は6^4=1296パターン、アクションは2パターンの計2592個のQ値となります。

■報酬の与え方
1回のエピソードは、ポールを立てるのを失敗する(ポールの角度が±0.2以上になるか、画面からはみ出る)か、成功する(200stepの間ポールを立て続ける)かです。
1stepごとにその時のQ値に対して報酬を1貰えます(1エピソードで最大合計200の報酬を得る)が、失敗したらその時のQ値に対して(継続step数-200)のペナルティを与えます。
これは長く続けることができたらペナルティは少なくなるという考えです。
本来は、ポール立てを失敗したらその時の行動だけではなく、失敗に至った原因となる1エピソード全ての行動にペナルティを与えるべきですが、今回はそうしておりません。
それでもそれなりに学習して、最終的にはポール立てを成功させています。
■Pythonによるシミュレーション
Q値を学習しポール立てを成功し続ける様にします。学習結果は「Qvalue.txt」というファイルに保存されます。
・pythonバージョン:Ver3.8で確認
・必要ライブラリ:numpy , OpenAI gym(インストール方法はこちら)
・プログラムファイル:cartpole.zip
シミュレーション結果は以下のとおり。エピソードが進むに従い受け取る報酬が多くなっていき、報酬が200になる回数(成功した回数)が増えているのが解ります。
なお、アニメーションは50エピソードずつしか表示しませんが、学習はきちんとエピソード毎になされています。
episode: 189 reward_sum: 200.0
episode: 190 reward_sum: 200.0
episode: 191 reward_sum: 200.0
episode: 192 reward_sum: 200.0
episode: 193 reward_sum: 200.0
episode: 194 reward_sum: 200.0
episode: 195 reward_sum: -64.0
episode: 196 reward_sum: 200.0
episode: 197 reward_sum: 200.0
episode: 198 reward_sum: -43.0
episode: 199 reward_sum: 200.0
<学習結果の検証>
学習したQ値の効果を確認するため、実行ステップ数を制限しないで倒立振子を動かしてみます。(Q値の更新も無し)
上記で学習したQ値を読み込みます。
・プログラムファイル:cartpole_test.zip
結果、長い間倒立振子を立て続ける事ができています。
■DQN(Deep Q Network)を使う
より複雑な問題に対してはDQNが有効ですが、DQNを使ってCartpole問題を解きます。こちら。
サブチャンネルあります。⇒ 何かのお役に立てればと
|
|