| 公開日:2020/3/29 , 最終更新日:2021/5/5
|
・In English
前提知識
・機械学習とは
■強化学習とは
強化学習(reinforcement learning)とは機械学習の一種で、どの様な状態が望ましい状態かを定義し、
その状態になったら学習器に報酬を与え、学習器はその時の状態と行動を学習し、報酬を最大化するような行動を選択していくというものです。
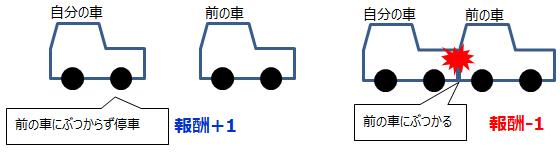
強化学習が使用されている身近な例に、自動運転や、将棋をするコンピュータなどがあります。自動運転に求められる動作は、目的地に人や物にぶつからずにたどり着く事ですが、
強化学習にはどんな時にどんな行動をするかという具体的なアルゴリズムは実装されておらず、経験を通じて最適な動作を自ら学習していきます。
どのような行動が最適かは運転時の状況によって変わるので、正解はなく教師というのは存在しません。ただしもっともらしい行動をした時には報酬を与え、そうでない時はペナルティを与える事で学習させます。
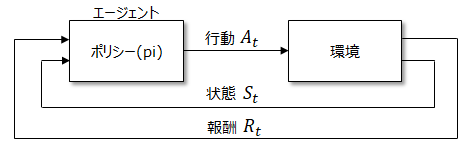
以下は強化学習の概念図です。エージェント(agent)は、報酬を最大限に得れると考える方策(ポリシー)に基づいて行動A(action)を決定します。
行動は環境(environment)に影響を与え、環境は行動の結果である状態S(state)と、それが良かったのかどうかを報酬R(reward)としてエージェントに返します。
エージェントはその報酬に基づいて改めて方策を見直し、再び行動を決定します。
これを制御工学の世界に当てはめると、エージェントは制御器、環境は制御対象物で、狙いの動作になるように状態をフィードバックしているのと同じ意味合いになります。
この様に、機械学習と制御工学の世界は考え方は一見同じなのに言い方が違ったりと、ある意味方言のような言葉遣いがよくあります。
■強化学習の種類
強化学習の良否はいかに優れた方策を決定するかにかかっており、方策を学習するための様々な手法が提案されています。以下はその手法の関係性を示した図例となります。
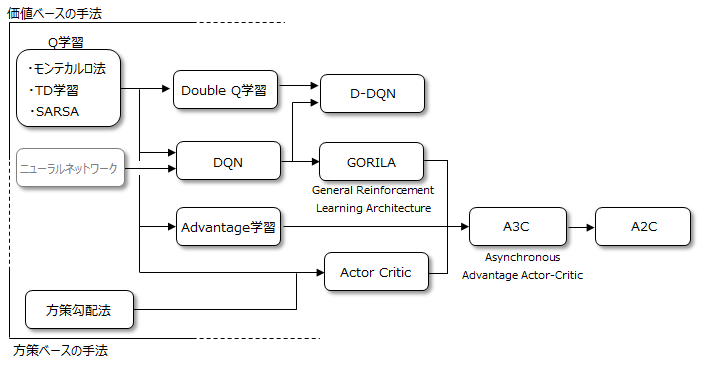
方策を学習する方法は大きく分けて2種類あります。
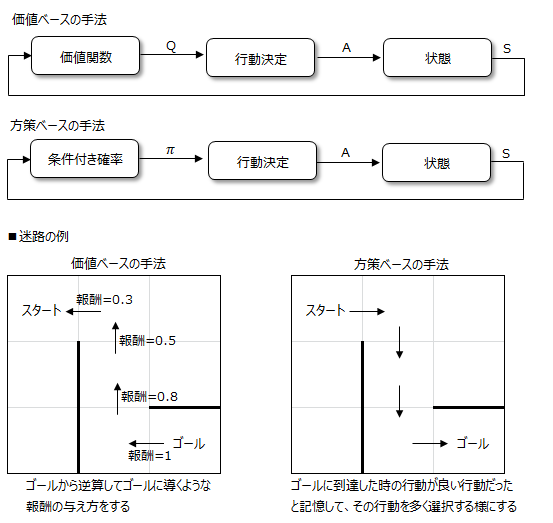
<価値ベースの手法:Value-Based Method>
価値ベースの手法は、価値関数QをTD学習やモンテカルロ法などにより学習し、この関数のもとで最適な行動を決定します。
行動は決定論的となる傾向があります。価値関数は、狙いの状態から逆算して、一つ前の状態、更に一つ前の状態が選択されるように報酬を与えます。
<方策ベースの手法:Policy-Based Method>
方策ベースの方法は、方策の条件付き確率πを方策勾配法などにより学習し、価値関数を求めることなく直接的に方策を決定します。
条件付き確率は、早く狙いの状態に達した時の行動は重要だと考え、その行動を今後多く取り入れる様に計算します。行動の選択は確率論的となります。
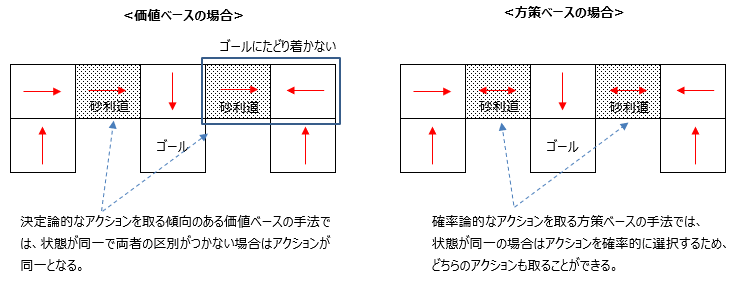
価値ベースの手法と方策ベースの手法の比較
<方策ベースの手法の利点>
① 価値ベースの手法は役に立たない可能性のある膨大な各状態に対するアクション値を保存する必要がありますが、方策ベースの手法はそうすることなく、
最適なポリシーを直接推定できる。
② 方策ベースの手法は、連続的なアクションが存在する場合に最適で、真の確率的ポリシーを学習することができる。
③ 価値ベースは決定論的なアクションを取る傾向があるので、本来は異なる状態であるが観測上は同一の状態がある(Aliased state)場合には
同一のアクションとなるので、以下の例ではゴールに到達できない場合があります(ε-greedy法を使用すると、他の状態の場合で最適な行動をとれなくなる)。
対して方策ベースは、同一の状態に対しても確率論的にアクションを選択できるので、ゴールにきちんと到達できます。
■強化学習の実装例
① 強化学習の理解のため、簡単なスキナー箱を題材にしたTD学習(Temporal Difference learning)の実装例をこちらで説明します。
初めての方は先ずはこちらから見る事をお勧めします。
② ①で理解を深めたら、次にもう少し複雑な事例を題材として、倒立振子を題材にしたTD学習の実装例をこちらで説明します。
③ 強化学習の精度を高める手法として、Deep Q-Network(DQN)の実装例をスキナー箱を題材に、こちらで説明します。
TD学習より複雑な問題を解くことができるため、DQNはよく使われる手法です。
④ 倒立振子を題材に、DQNで実装する例をこちらで説明します。
■強化学習のその他手法の説明
<モンテカルロ法>
こちらで説明
<Double DQN:D-DQN>
DQNでは行動を選択するネットワークとQ値を求めるネットワークが同じですが、選択された行動に対して過学習してしまいやすくなります。それを抑えるために、前の時刻で学習していた別のネットワークを使って行動を評価するのがDDQNです。
<Dueling DQN>
Q関数を状態だけで決まる部分と、行動によって決まる部分を分けて求め、最終的にはその両者のQ関数から行動を決定します。
Duelingという言葉から、エージェントを複数持つMulti-Agent Reinforcement Learningかと思いますが、それとは異なります。
<Actor Critic>
行動を選択するネットワークとQ値を求めるネットワークを完全に切り分けて学習する方法です。
<Asynchronous Advantage Actor-Critic:A3C>
Asynchronousは、複数のエージェントを用意してオンライン(時系列)で学習することを意味します。
Advantageは、DQNでは1ステップごとの行動を評価していますが、これをkステップ先までの行動まで同時に評価して学習します。これによって学習速度を速めます。
サブチャンネルあります。⇒ 何かのお役に立てればと
|