Reinforcement learning is a type of machine learning that defines what kind of state is desirable, gives a reward to the learner when it reaches that state, and the learner learns the state and action at that time,
The goal is to choose the behavior that maximizes the reward.
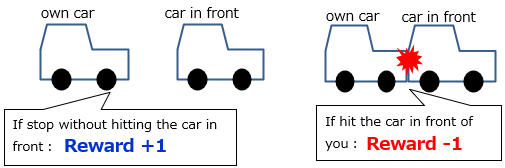
Use cases for reinforcement learning include self-driving cars and computers playing chess.
The behavior required for autonomous driving is to reach the destination quickly without colliding with people or objects, but reinforcement learning is not a conditional branching algorithm that determines what action to take at what time.
It learns the best behavior through experience
There is no correct answer and there is no teacher, because what action is best depends on the situation when driving.
It learns by giving a reward when it behaves plausibly, and giving a penalty when it does not.
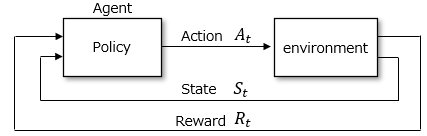
Below is a conceptual diagram of reinforcement learning. Agents decide actions based on policies that maximize rewards.
Actions affect the environment, and the environment rewards the agent with the state resulting from the action and whether it was good or not.
Based on the reward, the agent reviews the policy again and decides the action again.
If we apply this to the field of control engineering, the agent is the controller, and the environment is the object to be controlled.
■Types of reinforcement learning
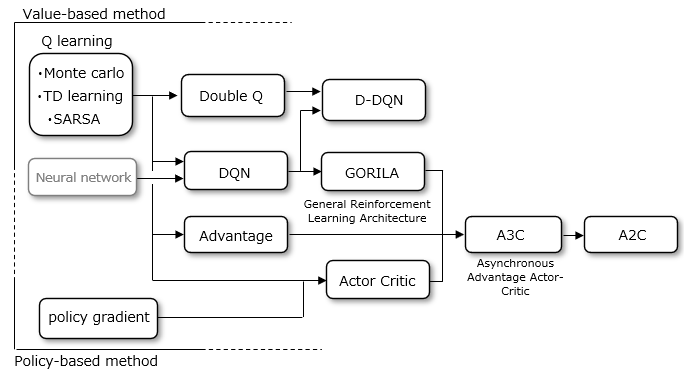
The quality of reinforcement learning depends on how well the policy is determined, and various methods have been proposed for learning the policy. Below is an example diagram showing the relationship between the methods.
There are two ways to learn policies.
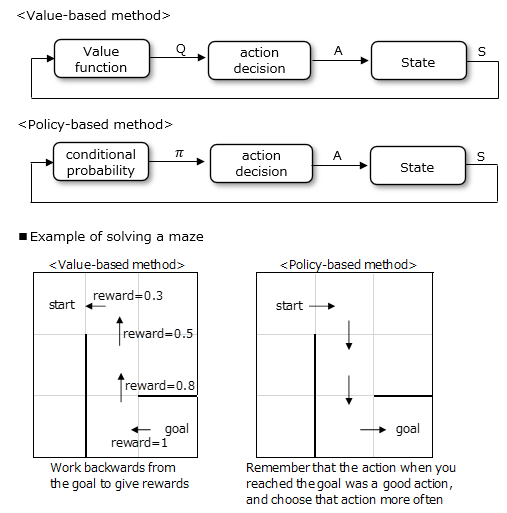
<Value-Based Method>
The value-based method learns the value function Q by TD learning, Monte Carlo method, etc., and determines the optimal action.
Actions tend to be deterministic. The value function works backwards from the target state and rewards the previous state to be selected.
<Policy-Based Method>
The policy-based method learns the conditional probability π of the policy using the policy gradient method, etc., and determines the policy directly without obtaining a value function.
Conditional probability is calculated so that the action when the target state is reached quickly is considered important, and that action is selected more often.
Action selection becomes probabilistic.
Comparing value-based and policy-based method
<Advantages of the policy-based method>
① The policy-based approach can directly estimate the optimal policy, while the value-based approach needs to store potentially useless, huge action values for each state.
② Policy-based approaches are best in the presence of sequential actions and can learn true probabilistic policies.
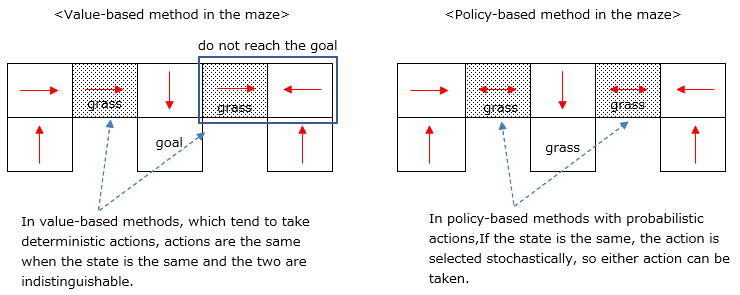
③ Value bases tend to take deterministic actions, so that states that are different in nature but have the same observational state (Aliased states) will have the same action.
The example below may fail to reach the goal (using the ε-greedy method leads to sub-optimal behavior in other states).
On the other hand, the policy-based method can select actions probabilistically even for the same state, so the goal can be reached properly.
■Implementation example of reinforcement learning
① To understand reinforcement learning, here is an implementation example of TD(Temporal Difference) learning using a simple Skinner box as a subject.
I recommend that you check first.
② After deepening your understanding in ①, next, I will explain an implementation example of TD learning using an inverted pendulum as a subject, using a slightly more complicated case as a subject.
Click here.
③ As a method to improve the accuracy of reinforcement learning, an implementation example of Deep Q-Network (DQN) is explained here using the Skinner box as a subject.
DQN is a popular technique because it can solve more complex problems than TD learning.
④ An example of implementation using DQN using an inverted pendulum is explained here.
<Double DQN:D-DQN>
In DQN, the network that selects actions and the network that obtains the Q value are the same, but it is easy to overfit for the selected actions.
To prevent overfitting, DDQN evaluates actions using a different network that was trained at the previous time.
<Dueling DQN>
The part of the Q function that is determined only by the state and the part that is determined by the action are obtained separately, and finally the action is determined from the Q functions of both.
From the word Dueling, you may think it is Multi-Agent Reinforcement Learning with multiple agents, but it is different.
<Actor Critic>
It is a method of learning by separating the network that selects actions and the network that obtains the Q value.