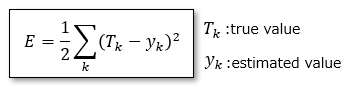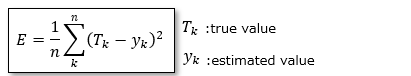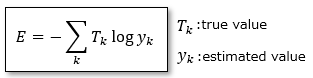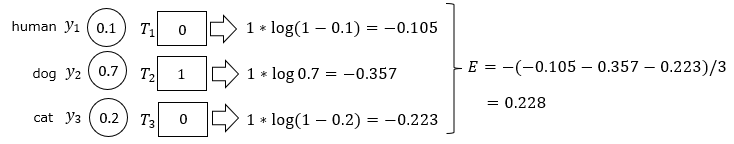In machine learning, etc., the error function evaluates the accuracy of a model based on the error between the true value and the model's estimated value. Also called loss function.
Error functions include error sum of squares and cross-entropy error, and if the value obtained from this error function is small, it can be said that the estimated value is close to the true value.
■Sum of squares error
This idea is also used in the least squares method, and takes the square of the difference between the true value and the error.
The reason for multiplying by 1/2 is to eliminate the coefficient when differentiating this function when calculating the minimum error value.
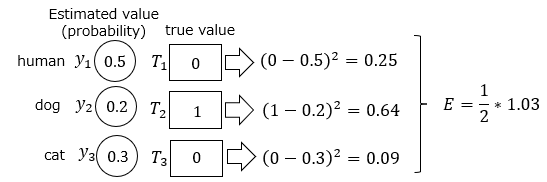
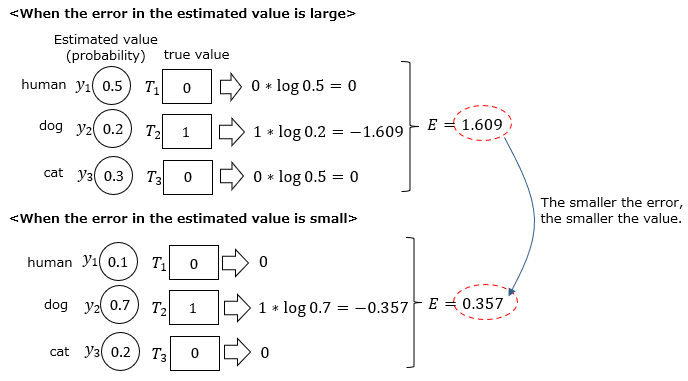
Let's consider a concrete example. There is machine learning that distinguishes between images of people, dogs, and cats, and while the correct answer was a dog, the machine learning incorrectly estimated that it was most likely a person.
At this time, the error function value is as follows.
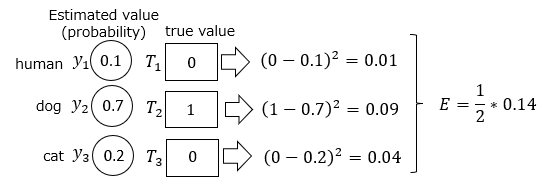
Machine learning then correctly estimated that it was likely a dog. You can see that the error function value decreases as you get closer to the correct answer.
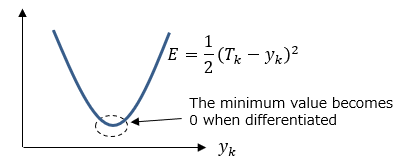
<Minimum value of error function>
Since this error function is a quadratic function, in order to calculate the minimum value, it is sufficient if the result of differentiating the function approaches 0.
In machine learning, we use the gradient method to find the minimum value.
■:Mean Square Error(MSE)
The form is similar to the sum of squares error, but there is also a way to calculate the loss in this form.
■Cross Entropy Loss
It can be expressed by the following formula. The base is the natural logarithm e.
Calculate the error function using the same example as before. The smaller the error in the machine learning estimate, the smaller the error function value.
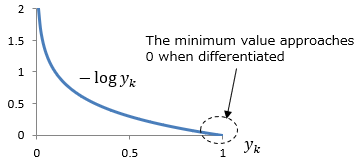
<Minimum value of error function>
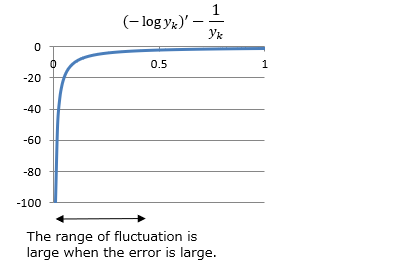
The logarithm has a graph like the one below, so to find the minimum value, the result of differentiating the function should be close to 0.
<Advantages of cross-entropy error>
Which is better: sum of squares error or cross entropy error? It seems that cross-entropy error is more often used.
The error function needs to be easily differentiated in order to find the minimum value, but since both are easy to differentiate, there is no significant difference.
The characteristics of the function after differentiation are that the differentiation of the sum of squares error is a linear property, whereas the differentiation of the cross entropy error is an inversely proportional property, and the larger the error, the greater the fluctuation of the function.
It has the advantage of high learning efficiency. This is why cross entropy error is used.
<Binary Cross Entropy Loss>
For the above cross entropy error, the error function expressed by the following formula is called Binary Cross Entropy Loss. Click here for a python implementation example.
■Why do we need an error function?
The error function is used to measure the accuracy of machine learning, but why is it necessary?
After all, accuracy can be determined by looking at the correct answer rate of the test results, and error squares are used to reduce errors when using the gradient method, but the sum of the error squares is not necessary.
Therefore, you may think that the error function is not necessary, but it plays an important role in measuring the accuracy of learning.
This is because the correct answer rate does not change slowly when the parameter is changed, or the correct answer rate can change abruptly with discontinuous values, so the correct answer rate is actually not suitable for measuring the validity of the parameter.