| 公開日:2021/10/5 , 最終更新日:2022/8/27
|
・In English
前提知識
・スクレイピング
・python
スクレイピング技術を使って、web上の画像をpythonで一括ダウンロードする方法を説明します。
これは機械学習などで大量の画像を入手する際に有効な手法となります。
■htmlにおいて画像ファイルはどのように定義されているか
htmlのソースコード上において画像ファイルは以下のように定義されておりますが、imgタグから画像情報を識別し更にsrcタグで画像のアドレスを取得します。

なおサイトによっては、以下の様にドメインが指定されていない表記の場合がありますが、今回説明するプログラムではこの表記には対応していません。(ドメイン名を取得して画像ファイル名と結合すれば保存可能)
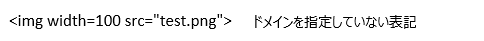
■画像ダウンロードのpythonによる実装例
<一つの画像をアドレス指定でダウンロードする例>
まずは最も簡単なプログラムで一つの画像を保存する例を説明します。requestsというライブラリをインストールします。
下記urlはテスト用のページとして存在しているため、下記プログラムはそのまま実行可能です。
import requests
img_url = "https://taketake2.com/PID77.jpg" # ファイルのアドレス指定
with open("PID77.jpg", 'wb') as f:
f.write(requests.get(img_url).content) # ファイル保存
<複数の画像を自動でダウンロードする例>
BeautifulSoupというライブラリは、指定したurlのソースコードを取得しますので、そこから画像データのアドレスを抽出します。画像のアドレスが分かれば、後は上記の様に画像を保存していきます。
import requests
from bs4 import BeautifulSoup
img_list = []
url = 'https://taketake2.com/test.html' # 任意のurlを指定
url_cont = BeautifulSoup(requests.get(url).content,'lxml') # url解析
img_all = url_cont.find_all("img") # imgタグ情報を取得
for d in img_all: # imgタグ情報を一つずつ抽出
d = d.get("src") # src情報を取得
if d.startswith("http") and (d.endswith("jpg") or d.endswith("png")):
img_list.append(d) # srcの末尾が.jpgか.pngの場合リストに追加
for img_data in img_list: # 画像データをファイルに保存
with open(img_data.split('/')[-1], 'wb') as f:
f.write(requests.get(img_data).content) # ファイル保存
print(img_data.split('/')[-1]) # 保存ファイル名出力
■注意点, プログラムがうまく動作しないケース
webサイトによっては画像ダウンロードを禁止しているところもあります。それは著作権保護の観点とWebページを表示するサーバーに負荷をかける場合があるという観点からです。 そのサイトの利用規約をよく確認しましょう。
またwebソースの取得自体ができないサイトもあり、上記プログラムで取得したwebページの内容が、実際取得したいページのソースと一致しない場合があります。プログラムがうまくいかない場合はそういった観点でプログラム実行結果を確認しましょう。
サブチャンネルあります。⇒ 何かのお役に立てればと
|